

#Blog
I'm not dead (yet)
It’s true it’s been a long time I didn’t posted anything on vmdude.fr, but believe me a lot happened since 2016 😄 Next blogpost will …
Continue ReadingIt’s true it’s been a long time I didn’t posted anything on vmdude.fr, but believe me a lot happened since 2016 😄 Next blogpost will …
Continue Reading
It gives an immense pleasure to be among the (very short, we’re just 32) 2016 VSAN vExpert list. Indeed, in this year 2016, VMware decided to …
Continue Reading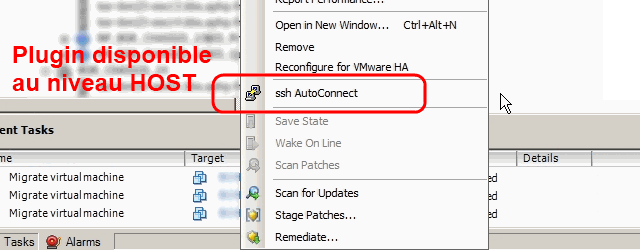
Update 2016/05/16: Thanks to @jmauser a Github release have been created that support vSphere 6.0 Update 2. You can download it here. Here is our …
Continue Reading
During our adventures in troubleshooting world, we met an interesting case with some challenge and a lot of laziness (and that’s the kind of …
Continue ReadingAs every year, VMware has released the list of vExpert for the year 2016 (available here with a little more than 1,350 entries, this community is …
Continue ReadingCela fait plusieurs fois que des personnes nous demande quelle est la procédure pour pouvoir bénéficier de SexiLog en HTTPS. par défault, …
Continue ReadingAs we follow up our previous post SolidFire vs ATS heartbeat about issues we had with SolidFire arrays, we had to disable another setting: DelayedAck …
Continue ReadingWe had to deal with an interesting case regarding a new VDI platform hosted on SolidFire arrays. During VM boot storm (around 1000 VM per cluster), we …
Continue ReadingFor those who are interested by SexiLog and/or Veeam™, or those who wish to have deeper knowledge about these two (awesome ^^) tools integration, we …
Continue ReadingFollowing Twitter news, we wanted to share with all of our readers the big news of this monday 23th march, 13h37, i.e. SexiLog official launch! This …
Continue Reading